2024.11.11 第一次会议
没有回答好的内容:
ASCII、Unicode编码,enum 和 enum class的区别
- ASCII、Unicode编码
ASCII码使用指定的7位或者8位二进制数组合来表示128或256种可能的字符。标准的ASCII码使用7位二进制数(剩下一位二进制位0)来表示所有的大写字母和小写字母,数字0-9、标点符号,以及在美式英语中使用的特殊控制字符。最后一位用于奇偶校验。
ASCII是单字节编码,无法用来表示中文,所以中国制定了GB2312编码,把中文编进去。
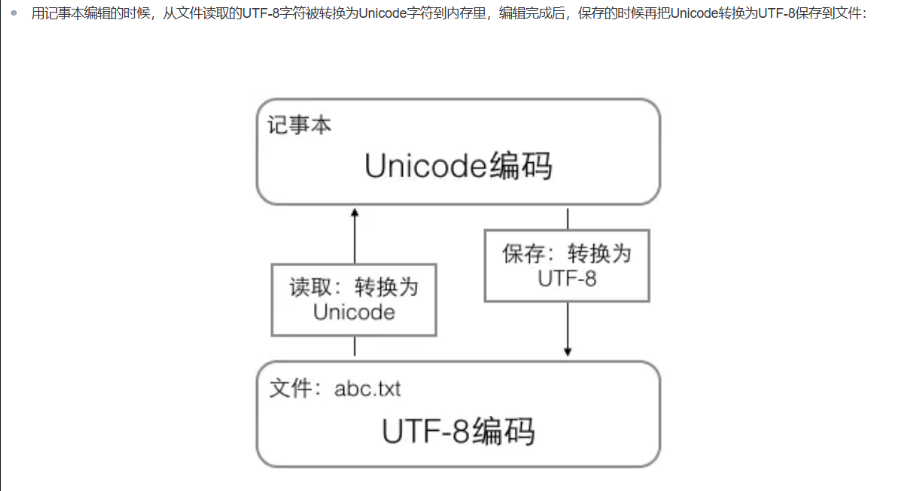
Unicode:把所有的语言都统一到一套编码里面,这样就不会有乱码的问题。最常用的是用两个字节表示一个字符(偏僻的字符使用4个字节)
UTF8 可变长编码,把一个Unicode字符根据不同的数字大小编码成1-6字节,常用的英文字母被编码成 1个字节,汉字通常是三个字节,只有生僻字才被编码成4-6个字节。传输的文本含有大量英文,使用UTF-8编码就能节省空间。

- enum 与 enum class
enum被称为不限定范围的枚举,enum class被称为限定范围的枚举
1️⃣enum是传统的枚举类型:
枚举值可以隐式转换成整数。
作用域:enum中的成员是全局的,可能导致名字冲突。两个枚举类型定义了相同的枚举变量名字,就会出现错误。
类型安全:不具备严格的类型安全,无意中与整数或其他枚举类型混用。
2️⃣enum class
作用域:enum class中的成员是局部与枚举类型本身的,不会造成名字冲突
显示转换:要将enum class 的成员转换成整数,必须使用static_cast
类型安全:enum class 更加安全,枚举值不会隐式转换为整数,必须显示转换
goto什么时候不能跳?
1️⃣跳转进入其他作用域:
goto不能跳转到一个不同作用域的标签。例如,不能从外部作用域跳转进入一个函数内部,或从循环或条件语句外部跳入其内部。2️⃣跨越对象的初始化:如果跳转会导致跨越具有非平凡析构函数的对象的初始化,则会出现编译错误。这是因为跳过对象初始化可能导致未定义行为,例如资源未正确分配。
3️⃣代替结构化控制语句:
goto语句通常不应当代替for、while、do-while等结构化控制语句,因为这样会使代码更难理解和维护。应优先使用这些结构化的循环和分支结构。4️⃣跨越内存管理代码块,在C++中,管理内存(如
new和delete)时不宜使用goto,因为容易导致资源泄露。用goto跳过特定的代码可能导致内存或资源未释放。
2024.11.18 第二次会议
没有回答好的问题:智能指针、左值右值
- 智能指针
智能指针是C++ 中用于自动管理动态内存的对象。它是一种特殊的类,通过封装普通指针的行为,实现自动资源管理(内存释放),从而避免常见的内存泄露和悬垂指针问题。
1️⃣ 独占型智能指针 std::unique_ptr
独占所有权,同一时间只能有一个std::unique_ptr管理某个资源,适用于需要明确表示所有权的场景。不可复制,但可以转移所有权。
示例
1 |
|
2️⃣ std::shared_ptr
共享所有权,多个std::shared_ptr可以共享同一种资源。适用于多个对象需要访问同一资源的场景。使用计数管理资源。引用计数为0时,资源才会被释放。
1 |
|
3️⃣ std::weak_ptr
弱引用,不参与引用计数管理。解决std::share_ptr的循环引用的问题。需要使用lock() 方法将 std::weak_ptr 转化为 std::shared_ptr来访问资源。
1 |
|
智能指针的优点:自动释放内存, 减少new/delete带来的麻烦。 避免内存泄露和悬垂指针问题。 代码更简洁、更安全。 用途:动态内存分配时,确保资源被独占管理且使用完成后自动释放。管理不需要共享的资源,如文件句柄、单线程对象等。
注意事项:
1️⃣ 不要同时使用普通指针和智能指针管理统一资源
2️⃣ std::shared_ptr 可能带来性能开销 (由于引用计数管理)。
3️⃣ std::weak_ptr 解决 std::shared_ptr的循环引用问题 。
循环引用问题 是指在使用智能指针(尤其是 std::shared_ptr)时,由于两个或多个对象互相引用对方,导致引用计数永远无法降为零,资源无法释放,造成 内存泄漏 的问题。
- 左值和右值
左值(lvalue, locator value)表示了一个占据内存中某个可识别的位置(也就是一个地址)的对象。
右值(rvalue)则使用排除法来定义。一个表达式不是 左值 就是 右值 。那么,右值是一个 不表示内存中某个可识别位置的对象的表达式。
1 | int var; |
赋值操作需要左操作数是一个左值。var是一个有内存位置的对象,因此它是左值。
1 | 4 = var; |
常量 4 和表达式 var + 1 都不是左值,因为它们都是表达式的临时结果,而没有可识的内存位置。
1 | int foo() {return 2;} |
1 | int globalvar = 20; |
这里foo返回一个引用。引用了一个左值,因此可以赋值给它。
C++ 中函数可以返回左值的功能对实现一些重载的操作符非常重要。下面是重载方括号操作符[],来实现一些查找访问的操作,如std::map 中的方括号。
1 | std::map<int, float> mymap; |
之所以能赋值给mymap[10], 是因为std::map::operator[] 的重载返回的是一个可赋值的引用。
可修改的左值
可以出现在赋值操作左边的值,但是加入const关键字后,这个定义不再成立
1 | const int a = 10; // 'a' 是左值 |
所以可赋值的左值被称为 可修改左值. C99标准定义可修改左值为:
可修改左值是特殊的左值,不含有数组类型、不完整类型、const 修饰的类型。如果它是 struct 或 union,它的成员都(递归地)不应含有 const 修饰的类型。
左值与右值的转换
左值可以转成右值
1 | int a = 1; // a 是左值 |
右值不可以转成左值,因为违反了左值的本质. 但是右值可以通过显式的方法产生左值.
例如, 一元解引用运算符 ‘*’ 需要一个右值参数, 但返回一个左值结果.
1 | int arr[] = {1, 2}; |
相反的,一元去地址操作符’&’ 需要一个左值参数,返回一个右值
1 | int var = 10; |
‘&’ 符号还有另一个功能—–定义引用类型. 引用类型又叫做”左值引用”. 因此不能将一个右值赋值给(非常量的) 左值引用:
1 | std::string& sref = std::string(); // 错误: 非常量的引用 'std::string&' 错误地使用右值 'std::string' 初始化 |
常量的 左值引用可以使用右值赋值。因为你无法通过常量的引用修改变量的值,也就不会出现修改了右值的情况。这也使得 C++ 中一个常见的习惯成为可能:函数的参数使用常量引用接收参数,避免创建不必要的临时对象。
CV限定的右值
一个非函数、非数组的类型 T 的左值可以转换为右值。 […] 如果 T 不是类类型【译注:类类型即 C++ 中使用类定义的类型,区别与内置类型】,转换后的右值的类型是 T 的 未限定 CV 的版本
每个类型都有三个对应的CV-限定类型版本: const 限定 volatile 限定 和 const-volatile 限定版本. 有或无CV限定的类型是不同的类型, 但是写法和赋值需求都是相同的.
1 |
|
main 中的第二个函数调用实际上调用的是 A 中的 foo() const 函数,因为 cbar 返回的类型是 const A,这和 A 是两个不同的类型。这就是上面的引用中最后一句话所表达的意思。另外注意到,cbar 的返回值是一个右值,所以这是一个实际的 CV 限定的右值的例子。
右值引用
左值和右值的主要区别是,左值可以被修改,而右值不能。不过,C++11 改变了这一区别。在一些特殊的情况下,我们可以使用右值的引用,并对右值进行修改。
使用 && 表示。它专门用于绑定右值,从而使程序可以操作右值(临时对象)。
用途: 1️⃣ 移动语义, 通过移动右值资源(如动态内存) 避免拷贝, 提升性能. 2️⃣完美转发:保留函数模板中参数的值类别(左值或右值)
1 |
|

Q: 如何判断一个表达式是左值还是右值?
1️⃣ 如果能取地址 (& 操作符能成功) , 则为左值
2️⃣ 如果不能取地址, 但可以用作右侧赋值, 则为右值
引用右值 主要是为了支持移动语义, 以减少不必要的资源拷贝, 以提高程序效率
总结 :
左值 : 有明确的内存位置, 生命周期可控, 可取地址.
右值: 临时值, 生命周期短, 通常不可修改.
右值引用:通过&&操作符,允许操作右值,主要用于移动语义和完美转发。
2024.11.25 第三次会议
没有回答好的内容: 数组指针、堆栈溢出
数组指针
1 |
|
p 指针指向包含五个整型元素的数组指针。注意这里的(*p)表明p是一个指针,而[5]表示它指向的对象是一个包含5个元素的数组。并且将 p 初始化为指向前面定义的数组 a 的地址(通过 &a 取数组 a 的地址来赋值给 p)
在这里,*p 实际上就是 p 所指向的那个包含 5 个整型元素的数组(因为 p 是指向数组的指针,解引用 *p 就得到它指向的数组本身)。
1 | printf("%p\n", a); |
printf("%p\n", a);:这里输出数组 a 的首元素地址,前面提到数组名在很多情况下可以代表首元素地址,所以它会输出数组 a 第一个元素在内存中的地址。
printf("%p\n", &a);:这里通过 &a 取的是整个数组 a 的地址,虽然数组首元素地址的值和整个数组的地址的值在数值上通常是一样的(在绝大多数常见的实现中),但它们的类型是不同的,一个是指向数组首元素的指针(int* 类型的指针),另一个是指向整个数组的指针(int (*)[5] 类型的指针)。
printf("%p\n", &a[0]);:这是取数组 a 的首元素 a[0] 的地址,其效果和直接使用 a (在代表首元素地址这个意义上)是一样的,同样会输出数组 a 第一个元素在内存中的地址。
指针数组
1 |
|
这里定义了一个名为 a 的数组,它包含 5 个元素,每个元素的类型都是 int*,也就是指向整型的指针类型。通过使用初始化列表 { },将这 5 个指针元素初始化为空指针(默认初始值)。本质上,a 是一个可以存放 5 个指向整型变量的指针的数组。
1 | int** p = a; |
二级指针初始化为a。之所以能这样赋值,是因为数组名 a 在这种情况下会隐式转换为指向数组首元素的指针, 而 a 的首元素类型是 int* ,所以 p 这个二级指针就可以指向 a 数组 (或者说指向 a 数组的首元素,首元素本身也是指针类型)。这意味着通过 p 可以间接操作 a 数组中的指针元素。
1 | int* (*p)[5] = &a; |
int* (*p)[5] 表示 p 是一个指针,它指向的是一个包含5个元素的数组,而这个数组中每个元素类型又是 int*
(指向整型的指针)。然后通过 &a 将 p 初始化为指向前面定义的 a 数组的地址。